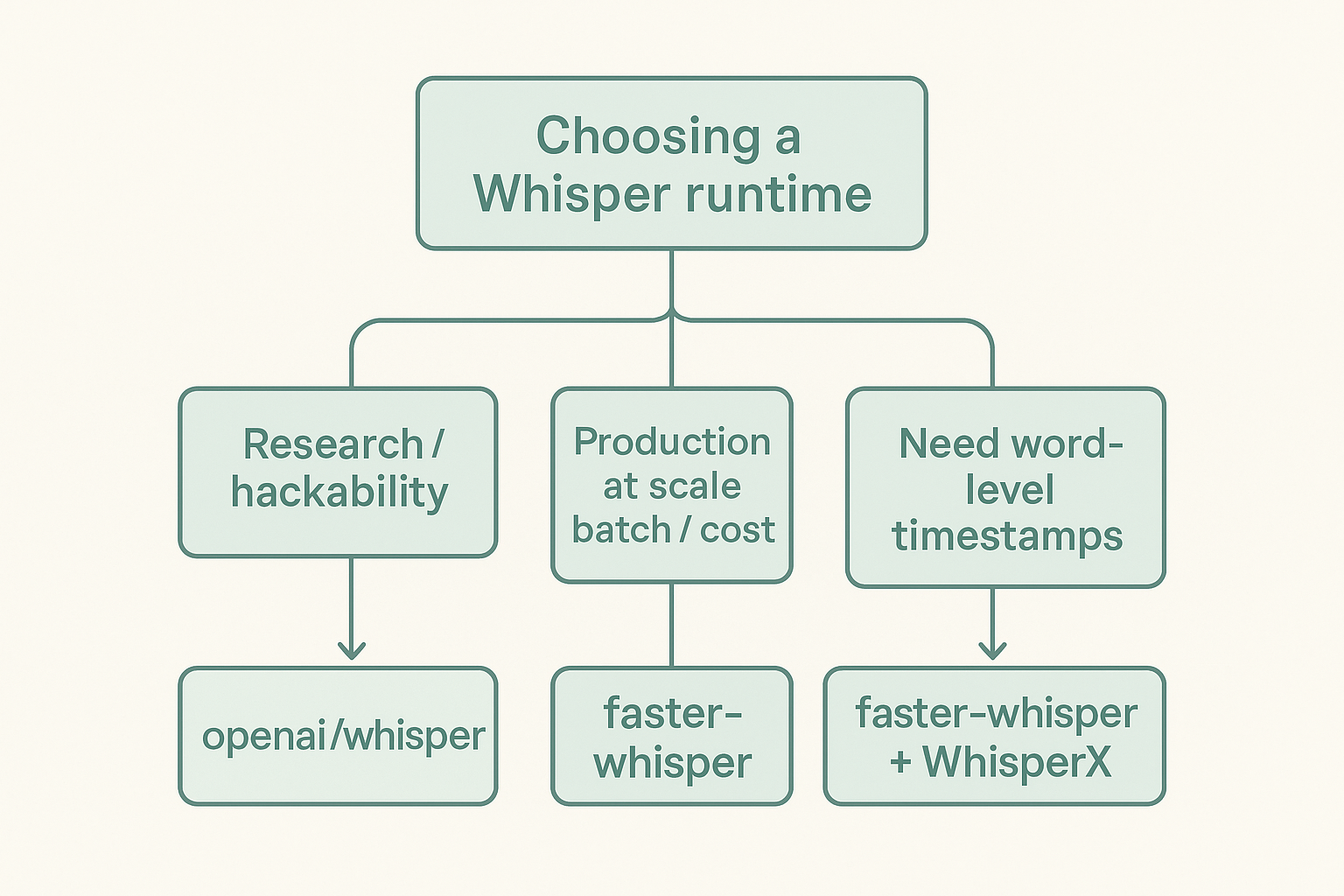
If you're picking between openai/whisper and faster-whisper for a real workload, the answer is short: same model weights, different runtime, faster-whisper wins on speed and memory at the same accuracy. The longer answer is what you're trading away to get there.
What they actually are
Both run the same family of Whisper models OpenAI released. The difference is the inference engine.
- openai/whisper is the reference Python implementation in PyTorch. Easy to install, easy to hack on, and the codebase the research papers point at.
- faster-whisper is a reimplementation on top of CTranslate2, a C++ engine purpose-built for fast Transformer inference. Same weights, different runtime — and that runtime is what makes the difference.
The actual tradeoff
| Criterion | openai/whisper | faster-whisper |
|---|---|---|
| Inference engine | PyTorch | CTranslate2 (C++) |
| Speed vs reference | 1× baseline | up to ~4× faster at the same accuracy (SYSTRAN benchmark) |
| Memory footprint | Baseline | Smaller (CTranslate2 + INT8 quantization on CPU/GPU) |
| Quantization (INT8/FP16) | Limited | First-class, both CPU and GPU |
| Accuracy | Reference | Equivalent (same weights, same decoding params) |
| Word-level timestamps | Yes | Yes |
| Batching for throughput | Limited | Strong (good for server workloads) |
| Ease of install | Pure pip | Pure pip; ships its own CTranslate2 wheels |
| Best fit | Research, hackability | Production, batch, anything self-hosted at scale |
On accuracy, the consensus across community testing is that if you feed both runtimes the same audio with the same decoding settings, the transcripts come out essentially identical — you're not trading quality for speed. The places they actually diverge are timestamp formatting and the exact behavior of voice-activity detection helpers some forks add on top.
When openai/whisper is still the right call
- You're prototyping, doing research, or modifying the model code.
- You need exact parity with a paper or a benchmark that pinned to the reference.
- You don't care about throughput and the simpler dependency story is worth more to you than 4× speed.
When faster-whisper is the obvious call
- You're self-hosting transcription for users or at scale.
- You care about cost per minute of audio — faster runtime means more throughput per dollar.
- You're running on CPU only and need INT8 quantization to make it viable.
- You're transcribing long files where the baseline runtime starts feeling painful.
There's also a third option worth knowing about: WhisperX wraps faster-whisper and adds forced alignment for precise word-level timestamps, which matters if you're building anything subtitle-shaped.
Paste any public link or upload a file and get a clean transcript in minutes. First 3 clips every month are on us — no card required.
Verdict
Pick openai/whisper if you're hacking on the model or you need reference parity. Pick faster-whisper for anything else — it's the same accuracy, several times the throughput, and what most people self-hosting Whisper at scale have quietly switched to.
Sources
- SYSTRAN faster-whisper benchmark — https://github.com/SYSTRAN/faster-whisper#benchmark
- Modal blog, "Choosing between Whisper variants" — https://modal.com/blog/choosing-whisper-variants
- Mobius Labs, "Speeding up Whisper" — https://mobiusml.github.io/batched_whisper_blog/


