Diarization error rate (DER) is the percentage of audio in a recording where your speaker labels are wrong. It is to speaker diarization what word error rate is to transcription: the single number a system gets judged on.
It's a different metric from WER, and the two often move in opposite directions. A transcript can be word-perfect and still have a 30% DER, which means a third of it is attributed to the wrong person. If you've ever read a Zoom transcript where Speaker 1 keeps "saying" things Speaker 2 actually said, you've lived inside high DER.
How DER is actually calculated
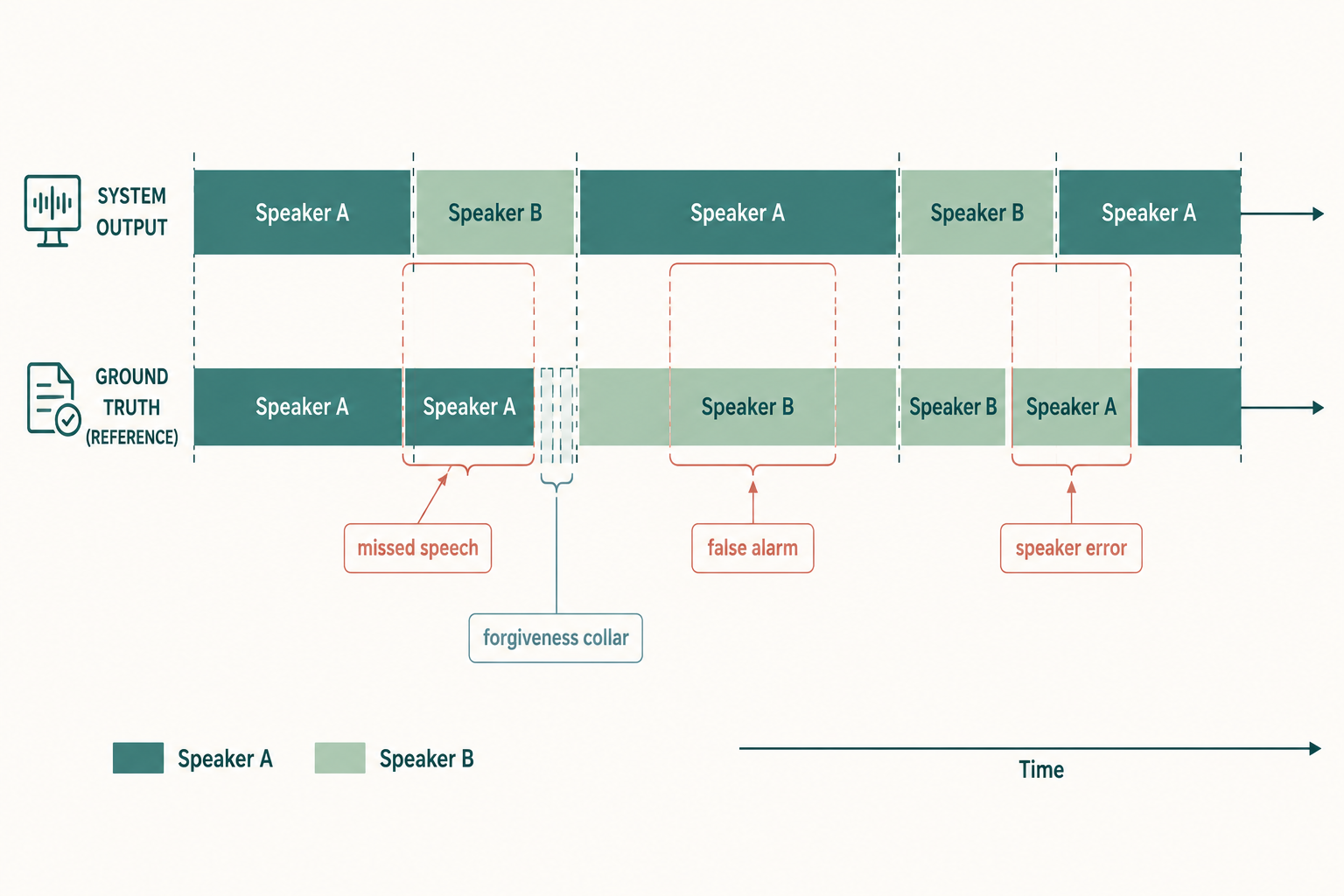
The score has three buckets, each measured against a ground-truth annotation of who spoke when:
- Missed speech — audio where someone was talking but the system marked silence.
- False alarm — audio the system labeled as speech but nobody spoke (often music, noise, or breathing).
- Speaker error — audio the system caught as speech but assigned to the wrong speaker.
DER = (missed + false alarm + speaker error) / total reference speech time.
The NIST Rich Transcription evaluations, where this metric became standard, also apply a small forgiveness collar around segment boundaries (usually 250 ms) so the score isn't dominated by millisecond-level boundary disagreements.
Two consequences of how it's built. First, overlap matters: if two people talk at once, the reference says both spoke, and a system that picks only one is penalized. Second, the labels themselves don't need to match. DER finds the best mapping between your "Speaker 1" and the reference "Alice". What counts is whether the audio assigned to the same person stays consistent.
How is DER different from WER?
WER is about what was said. DER is about who said it. You can be perfect on one and terrible on the other.
| Metric | Measures | Hurt by |
|---|---|---|
| WER | Word recognition | Noise, accents, jargon, model limits |
| DER | Speaker attribution | Overlap, similar voices, short turns, far microphones |
A clean dictation from one person has near-zero DER by default — one speaker, no confusion possible. A four-way Zoom with people interrupting can have a low WER and a brutal DER: every word transcribed, half of them assigned to the wrong head.
For the underlying mechanic, the plain-English explainer on speaker diarization covers how a system tries to separate voices in the first place. DER is just how we score that separation.
What counts as a good DER score?
There's no universal threshold, only the one for the kind of audio you have. Some honest reference points from published benchmarks:
- Clean two-speaker telephone speech — modern systems land in the 5–10% DER range.
- Meeting audio (multi-speaker, single far-field mic) — closer to 15–25% DER, with the AMI and ICSI corpora as the usual yardsticks.
- Highly overlapped or in-the-wild audio — 25–40% DER is common, and recent DIHARD challenge winners sit in that band.
If a vendor quotes "95% diarization accuracy," ask what corpus and what collar. Those numbers are not directly comparable to published DER unless they say so. For the broader picture of how transcription quality is reported, see what to expect from accuracy.
What drives DER up
In practice, four things explain most of the score:
- Overlap. Cross-talk and back-channels ("yeah," "mhm") are the single largest source of error in real meetings.
- Short turns. A speaker who interjects for half a second is hard to separate from the speaker around them.
- Similar voices. Same-gender, same-accent speakers are harder to tell apart than mixed groups.
- Microphone setup. A single laptop mic across a conference table averages everyone together. Per-speaker mics or per-participant tracks change the math entirely.
How do you lower DER on your own recordings?
You won't change the model, but you can change the input. The cheapest wins:
- Record one track per speaker when the platform allows it. Zoom and Riverside both offer per-participant tracks, and that single change can move DER from "useless" to "fine."
- Place a mic closer to each person. Far-field laptop pickup is the worst case.
- Moderate. Cut the simultaneous talk where you can — it costs nothing and pays the largest dividend.
- Relabel after the fact. Diarization gives you "Speaker A/B"; renaming them to real people takes minutes and is a separate step from the metric.
When you upload audio to transcribe a meeting, the diarization quality you get out is bounded by the audio quality you put in.
Should you compute DER on your own files?
Usually no. DER requires a hand-labeled reference, which is more work than just fixing the speaker labels in your transcript by hand. Compute it if you're evaluating a vendor or training a model. Otherwise, the practical equivalent is a quick scan: pick a few minutes, check whether the labels match reality, fix the obvious mis-assignments, and move on.
The metric is most useful as a vocabulary. Once you know that "who said what" has its own number, you stop blaming the transcriber for a problem that lives upstream in your microphone setup.
Paste any public link or upload a file and get a clean transcript in minutes. First 3 clips every month are on us — no card required.


