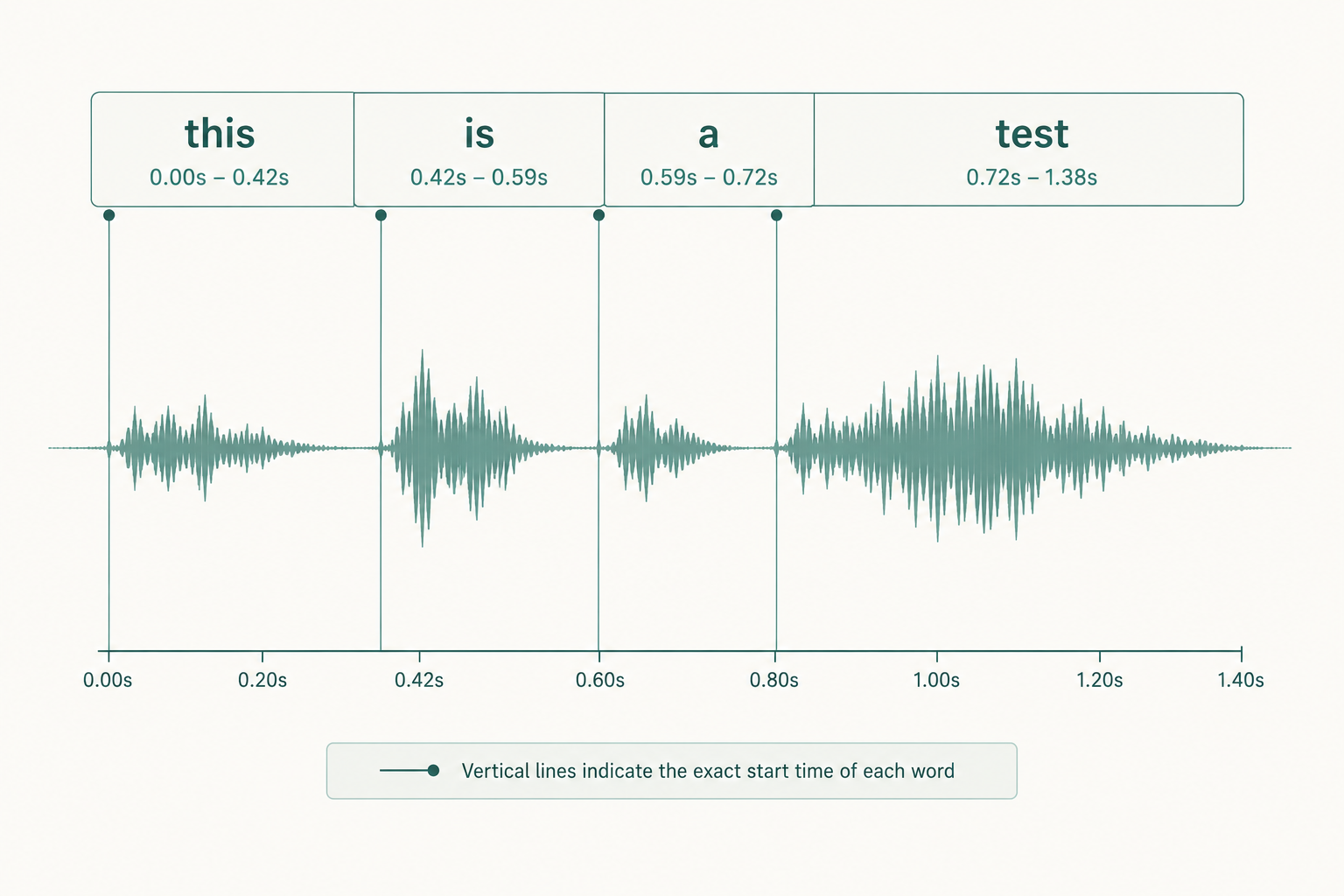
The first time you watch karaoke-style captions light up one word at a time on a YouTube short, you're seeing forced alignment do its job. The audio says "this is a test" and somebody, somewhere, decided that "this" starts at 0.42 seconds and ends at 0.59. That mapping (text in, time codes out) is forced alignment.
It sounds niche. It runs more transcription workflows than most people realize.
- Forced alignment maps a known transcript to its audio, word by word.
- It's the timing layer behind karaoke captions, click-to-play words, and tight subtitles.
- Most modern transcription tools do it automatically; you only need it as a separate step when you already have an authoritative transcript.
- It drifts when the transcript and the audio disagree, not when audio is "bad."
What is forced alignment, really?
Forced alignment takes a piece of audio and a piece of text that you already know is correct, and produces a third thing: a timestamp for every word (or phoneme) in the text.
"Forced" is the key word. The aligner isn't guessing what was said. It's been given the words. Its only job is to figure out when each one happens.
That's a much narrower problem than transcription, which is why it can be much more accurate at word boundaries.
How is it different from speech recognition?
Speech recognition (ASR) reads audio and tries to output text. It's solving "what was said?" with no help.
Forced alignment is given both inputs and only solves "when was each word said?". You feed it the audio and the script.
Most modern ASR engines bolt the two steps together. Whisper, for example, produces a transcript and a per-word timestamp in the same pass. The timestamps come from a built-in alignment step that uses the model's own attention as the signal.
The split matters when the transcript is already authoritative: a published script, a court record, a peer-reviewed interview. You don't want the ASR to "fix" the text. You want the timestamps that go with the text you already have.
For a deeper look at what ASR is actually doing under the hood, see what is word error rate (WER).
Why does it matter for transcription?
Three places where it earns its keep.
Subtitle timing. If you have a script and need an .srt, alignment turns the script into a perfectly timed caption file in seconds. No watching a video with a stopwatch.
Word-highlighting. Karaoke-style word-by-word highlighting, "click the word to jump to the audio," and waveform editors all rely on word-level timestamps. They're easy when you have them and painful to fake when you don't.
Linguistic and qualitative research. Phonetics labs measure vowel duration. Discourse analysts study turn-taking. Both need to know exactly when a word started and stopped, often to the millisecond.
If you cut video from spoken-word source material, the practical version of this is covered in timestamped transcripts for video editors.
Where does forced alignment break?
The honest answer: when the inputs disagree.
For clean audio with a known-good transcript, modern aligners land within about 50 ms of the true word boundary most of the time. That's well below the threshold where a human notices captions are off.
Accuracy slips on:
- Disfluencies (ums, false starts, mid-word stops). The transcript usually doesn't include them; the aligner has to either stretch a nearby word over the gap or fail.
- Overlapping speakers. Aligners assume one voice at a time. Crosstalk in interviews and meetings throws off the timing.
- Music and noise. A loud score eats consonants. The aligner can lose a few seconds and recover, but the recovery is rarely clean.
- Transcript errors. If the script says "John" but the audio says "Jonathan," the aligner has nowhere to put the extra syllables and timing slips for the rest of the line.
That last failure mode is why a clean transcript matters as much as clean audio. Garbage in, drift out.
If your captions look fine for the first minute and then drift later, alignment failure is usually the cause. The fix isn't to nudge timestamps by hand. Find the disagreement point and re-align from there. We walked through the symptoms in SRT out of sync: 6 fixes for subtitle timing drift.
Do I need forced alignment for captions?
If you're starting from audio with no script, no. You need transcription, which already produces timestamps. Forced alignment is the answer when you already have the right text and just need it timed.
Common "yes you do" scenarios:
- A producer hands you a finalized script and the recorded read.
- You have an old transcript and a higher-quality re-record of the same source.
- You're publishing the print version of an interview and want captions that exactly match the printed text, not what the speaker actually mumbled.
In every other case, run a modern ASR pass. It gives you the transcript and the timestamps together. You can transcribe a file with word-level timestamps in one step and skip the separate alignment step entirely.
What tools do forced alignment?
Open source:
- Montreal Forced Aligner (MFA). The de facto standard for academic research. Handles many languages with downloadable acoustic models. Steep setup; rewarding output.
- Gentle. A friendlier wrapper around Kaldi for English. Easy to run locally; older but still useful.
- aeneas. Text-to-audio alignment at the sentence and fragment level, popular for audiobook syncing.
In ASR systems:
- Whisper and faster-whisper produce word-level timestamps as part of transcription. Pass
word_timestamps=Trueand the per-word timing comes back in the result. - Commercial APIs (AssemblyAI, Deepgram, Speechmatics, Google) return per-word timing by default.
For most people writing captions, the right move is the ASR-with-timestamps path. Forced alignment as a separate step is for when you specifically have a transcript that must not change.
How does it relate to speaker labels?
It doesn't, directly. Forced alignment tells you when each word was spoken. Speaker diarization tells you who spoke. Most full transcription pipelines run both (alignment for timing, diarization for attribution) and merge the outputs at the end.
When word labels and speaker labels both look wrong in the same place, you're usually seeing one of two things: a missed speaker change (diarization), or alignment drift across that change (alignment). The fix is different for each.
Paste any public link or upload a file and get a clean transcript in minutes. First 3 clips every month are on us — no card required.


